LLM không "hiểu" tiếng Việt — nó đoán từ tiếp theo. Mỗi câu trả lời ChatGPT đưa cho bạn là một chuỗi vài trăm lần đoán, mỗi lần chỉ chọn một token có xác suất cao nhất trong toàn bộ kho từ. Bài này giải thích LLM (large language model — mô hình ngôn ngữ lớn) thực ra là gì, hoạt động ra sao, và vì sao GPT, Claude, Gemini, Llama đều cùng họ.
Nguồn: Large language model — Wikipedia
LLM là gì?
Theo định nghĩa của Wikipedia, LLM là "a language model trained with self-supervised machine learning on a vast amount of text, designed for natural language processing tasks, especially language generation" — một mô hình ngôn ngữ được huấn luyện bằng học máy tự giám sát trên khối lượng văn bản khổng lồ, chủ yếu để sinh ngôn ngữ.
Hai chữ "large" (lớn) không phải để cho kêu. Chúng nói tới hai con số cụ thể:
- Số tham số — từ vài tỷ đến hàng trăm tỷ trọng số bên trong mạng nơ-ron. Llama 4 Scout dùng kiến trúc mixture-of-experts với 17 tỷ tham số hoạt động.
- Lượng dữ liệu huấn luyện — hàng nghìn tỷ token văn bản từ internet, sách, code, bài báo.
LLM nằm ở tầng cụ thể nhất trong cây phân loại: AI → Machine Learning → Deep Learning → LLM. Nếu bạn chưa rõ bốn tầng này khác nhau ra sao, đọc AI là gì trước.
Mọi LLM bạn dùng hôm nay — ChatGPT (GPT-4.1, GPT-5.5), Claude (Sonnet 4.5, Opus 4.7), Gemini (2.5 Pro, 3 Pro), Llama (4 Scout, 4 Maverick) — đều dùng chung kiến trúc gốc: transformer.
LLM hoạt động như thế nào?
Cốt lõi đơn giản đến bất ngờ. Theo Duke University Libraries, "LLMs use math (or statistical pattern matching) to predict the probable next word or idea" — LLM dùng toán (cụ thể là khớp mẫu thống kê) để dự đoán từ hoặc ý kế tiếp có xác suất cao nhất.
Khi bạn gõ "Thủ đô của Pháp là", mô hình không tra cứu cơ sở dữ liệu. Nó:
- Cắt câu thành các token (từ, một phần của từ, hoặc dấu).
- Đẩy chuỗi token qua hàng chục lớp mạng nơ-ron.
- Ở đầu ra, tính xác suất cho từng token có thể đứng tiếp.
- Chọn token có xác suất cao — thường là "Paris".
- Nối "Paris" vào chuỗi, quay lại bước 2, đoán tiếp.
Một câu trả lời dài 300 từ là 400–500 lần lặp lại vòng đó.
Kiến trúc transformer
Nguồn: Attention Is All You Need — Wikipedia
Bước nhảy lớn đến từ bài báo "Attention Is All You Need" do tám nhà nghiên cứu Google công bố tại hội nghị NeurIPS năm 2017. Họ vứt bỏ kiến trúc tuần tự (RNN) đã thống trị xử lý ngôn ngữ trước đó, thay bằng cơ chế self-attention cho phép mô hình "nhìn" tất cả token cùng lúc thay vì đọc từ trái sang phải.
Vì sao điều này quan trọng: self-attention chạy song song trên GPU, cho phép huấn luyện trên dữ liệu lớn hơn và nhanh hơn nhiều lần. Mọi LLM hiện đại đều xây trên nền transformer — bài báo này đã được trích dẫn hơn 173.000 lần.
Ba giai đoạn huấn luyện
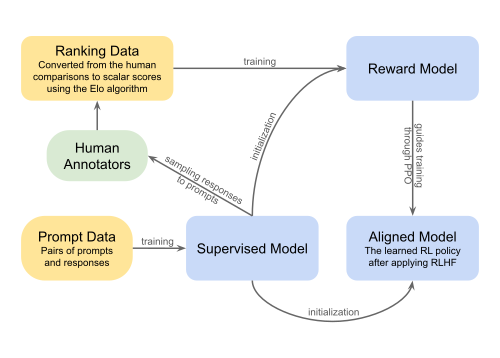
Nguồn: Reinforcement learning from human feedback — Wikipedia
Một LLM thương mại như ChatGPT không xuất xưởng chỉ sau một lần "ăn" internet. Nó qua ba giai đoạn:
- Pretraining — mô hình nuốt hàng nghìn tỷ token văn bản, học mẫu thống kê: ngữ pháp, sự kiện, mối quan hệ giữa các khái niệm. Đây là pha tốn kém và tốn điện nhất, có thể mất hàng tháng trên hàng nghìn GPU.
- Supervised fine-tuning (SFT) — con người viết hàng nghìn ví dụ "câu hỏi → câu trả lời mẫu". Mô hình học cách trả lời theo lệnh thay vì chỉ hoàn thành câu.
- RLHF (Reinforcement Learning from Human Feedback) — người đánh giá xếp hạng các câu trả lời của mô hình. Một reward model học từ xếp hạng này, rồi dùng để tinh chỉnh LLM theo hướng câu trả lời con người thích hơn. Theo Wikipedia, kỹ thuật này được dùng cho "OpenAI's ChatGPT and InstructGPT, DeepMind's Sparrow, Google's Gemini, and Anthropic's Claude".
Sau ba pha, mô hình mới biết trả lời lịch sự, từ chối câu hỏi nguy hiểm, và bám sát ý người dùng. LLM thô (chỉ pretraining) thường lan man và không thể dùng làm trợ lý.
Context window là gì và tại sao bạn cần quan tâm?
Context window là số token tối đa mô hình "nhìn" được trong một lượt — bao gồm cả prompt của bạn và câu trả lời nó sinh ra. Vượt giới hạn này, phần đầu hội thoại bị cắt và mô hình "quên" nội dung đó.
Số liệu năm 2026 theo AIMultiple:
| Mô hình | Context window |
|---|---|
| Claude Sonnet/Opus | 200.000 token (1 triệu beta cho tier 4+) |
| GPT-4.1 | 1 triệu token |
| Gemini 2.5 Pro | 2 triệu token |
| Llama 4 Scout | 10 triệu token |
Một triệu token tương đương khoảng 750.000 từ — đủ chứa cả bộ Harry Potter và Hòn đá Phù thủy bảy lần. Trên giấy. Thực tế, AIMultiple cảnh báo "most models break much earlier than advertised" — chất lượng tụt rõ trước khi chạm đỉnh quảng cáo, mô hình hay bỏ sót thông tin giữa tài liệu (hiện tượng "lost in the middle").
Với bạn: context window lớn hữu dụng khi phân tích hợp đồng dài hoặc đọc cả codebase. Với chat hằng ngày, 200K của Claude đã thừa.
Những hiểu lầm nào về LLM bạn cần tránh?
"LLM hiểu ngôn ngữ như con người." Không. Nó khớp mẫu thống kê trên token. Hai câu nghĩa khác nhau nhưng cấu trúc bề mặt giống nhau có thể bị xử lý gần như nhau, và ngược lại. Đây là lý do LLM có thể trả lời câu lừa hoặc câu mơ hồ bằng giọng tự tin nhưng sai.
"Càng nhiều tham số càng giỏi." Không hẳn. Tham số chỉ là một yếu tố — chất lượng dữ liệu huấn luyện, kiến trúc, và pha RLHF quan trọng không kém. Mô hình nhỏ huấn luyện kỹ trên dữ liệu sạch có thể hơn mô hình lớn huấn luyện cẩu thả trên dữ liệu nhiễu.
"LLM biết mọi thứ vì đã đọc cả internet." Sai theo hai cách. Một, nó có ngày cắt huấn luyện — hỏi tin tuần này có thể nhận đáp án cũ. Hai, LLM bịa (hallucinate) khi sự kiện thưa hoặc mâu thuẫn trong dữ liệu huấn luyện. Duke Libraries chỉ ra: "LLMs are trained to produce the most statistically likely answer, not to assess their own confidence" — LLM được huấn luyện để xuất ra câu trả lời có xác suất cao nhất, không phải để đánh giá độ tự tin của chính nó. Đây là lý do mọi con số, ngày tháng, hoặc trích dẫn từ LLM cần được kiểm tra lại (xem thêm phần "Khi nào AI sai" trong AI là gì).
"Mỗi hãng có công nghệ riêng." Về kiến trúc cốt lõi thì không — GPT, Claude, Gemini, Llama đều là transformer biến thể. Khác biệt nằm ở quy mô tham số, dữ liệu huấn luyện, cách RLHF, và kỹ thuật suy luận (reasoning, tool use).
Bạn nên dùng LLM nào?
Câu trả lời thực dụng cho người mới: thử cả ba bản miễn phí trong tuần này, rồi chọn cái bạn thấy hợp giọng.
- ChatGPT (chat.openai.com) — phổ biến nhất, hệ sinh thái plugin và GPT tùy chỉnh phong phú.
- Claude (claude.ai) — mạnh ở viết và phân tích văn bản dài, ít bịa hơn theo cảm nhận nhiều người dùng.
- Gemini (gemini.google.com) — tích hợp sâu với Google Workspace, miễn phí nhiều hơn các đối thủ.
Đừng đọc thêm 10 bài so sánh trước khi mở một cái lên. Dán việc thật vào — viết một email, dịch một đoạn, tóm tắt một báo cáo — và xem hãng nào trả ra kết quả bạn cần ít sửa nhất.
Câu hỏi thường gặp
LLM khác chatbot ở điểm nào? Chatbot là sản phẩm, LLM là động cơ bên trong. ChatGPT là chatbot; GPT-4.1 là LLM chạy bên dưới. Một LLM có thể dùng cho chatbot, dịch, trợ lý code, hoặc gắn vào sản phẩm khác qua API.
"Large" trong LLM là large bao nhiêu? Không có ngưỡng chính thức. Thực tế, từ khoảng 1 tỷ tham số trở lên đã được gọi là "large". Các mô hình thương mại đóng (GPT-4.1, GPT-5.5, Claude Opus 4.7, Gemini 2.5 Pro) không công bố số chính xác — phỏng đoán của giới ngoài thường dao động từ vài trăm tỷ đến hàng nghìn tỷ tham số.
LLM có hiểu tiếng Việt tốt không? Có, nhưng không đều. GPT-4.1, Claude Sonnet 4.5, Gemini 2.5 Pro xử lý tiếng Việt tự nhiên cho phần lớn tác vụ. Với chuyên ngành hẹp (luật Việt Nam, kỹ thuật chuyên sâu) chất lượng giảm rõ vì dữ liệu huấn luyện tiếng Việt vẫn ít hơn tiếng Anh nhiều lần.
Tôi có thể chạy LLM trên máy mình không? Được, với các mô hình mở như Llama, Mistral, DeepSeek. Bản 7B–13B tham số chạy được trên laptop có 16GB RAM và GPU rời. Chất lượng không bằng GPT-4.1 hay Claude Opus nhưng đủ cho prototype. Công cụ phổ biến: Ollama, LM Studio.