Gmail chặn hơn 99,9% spam, Visa ngăn 40 tỷ USD giao dịch gian lận chỉ trong 12 tháng, AlphaGo thắng kỳ thủ Lee Sedol 4–1. Không hệ thống nào trong số đó "hiểu" bài toán — chúng chỉ là hàm toán học khớp với dữ liệu. Đó chính là Machine Learning (ML, học máy): nhánh của AI nơi máy tự rút ra mẫu từ dữ liệu thay vì được lập trình từng quy tắc.
Nguồn: Machine learning — Wikipedia
Machine Learning là gì?
Theo Wikipedia, ML là "a field of study in artificial intelligence concerned with the development and study of statistical algorithms that can learn from data and generalize to unseen data, and thus perform tasks without being explicitly programmed" — một lĩnh vực trong AI tập trung vào thuật toán thống kê học từ dữ liệu và tổng quát hóa cho dữ liệu mới, không cần lập trình tường minh.
Thuật ngữ "machine learning" do Arthur Samuel — kỹ sư IBM — đặt năm 1959 khi viết chương trình chơi cờ đam tự học. Định nghĩa hình thức của Tom Mitchell (1997) vẫn dùng đến nay: "A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P if its performance at tasks in T, as measured by P, improves with experience E" — chương trình "học" khi hiệu suất (P) trên tác vụ (T) cải thiện theo kinh nghiệm (E).
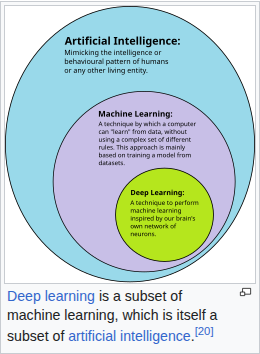
ML là tầng giữa trong cây phân loại AI → Machine Learning → Deep Learning → LLM. Nếu chưa rõ bốn tầng khác nhau ra sao, đọc AI là gì trước.
Machine Learning hoạt động như thế nào?
Lấy ví dụ bộ lọc spam Gmail. Theo Google Workspace, họ "rely on machine learning powered by user feedback to catch spam and help us identify patterns in large data sets" — dùng ML nuôi bằng phản hồi người dùng để nhận mẫu trong tập dữ liệu lớn.
Quy trình gồm ba bước:
- Dữ liệu huấn luyện — hàng tỷ email đã gắn nhãn "spam" hoặc "không spam" (từ nút Report spam của người dùng).
- Khớp hàm — thuật toán tìm hàm f(email) → xác suất là spam sao cho dự đoán càng khớp nhãn càng tốt. "Học" ở đây nghĩa là tinh chỉnh hàng triệu trọng số bên trong cho đến khi sai số nhỏ nhất.
- Dự đoán — email mới đến, mô hình tính xác suất, vượt ngưỡng thì đẩy vào Spam.
Không ai viết quy tắc "nếu chủ đề chứa 'trúng thưởng' và người gửi lạ thì là spam". Mô hình tự rút mẫu đó từ dữ liệu — và tự rút mẫu mới khi loại spam thay đổi.
Có mấy loại Machine Learning?
Giới nghiên cứu chia ML theo kiểu dữ liệu đầu vào và phản hồi, không phải theo công nghệ. Ba nhánh chính:
| Loại | Dữ liệu huấn luyện | Ví dụ thực tế |
|---|---|---|
| Có giám sát | Dữ liệu có nhãn (input → output) | Lọc spam, chấm điểm tín dụng, nhận dạng ảnh |
| Không giám sát | Dữ liệu không nhãn | Phân nhóm khách hàng, phát hiện bất thường |
| Tăng cường | Phần thưởng từ môi trường | AlphaGo, robot, RLHF trong ChatGPT |
Nguồn: Supervised learning — Wikipedia
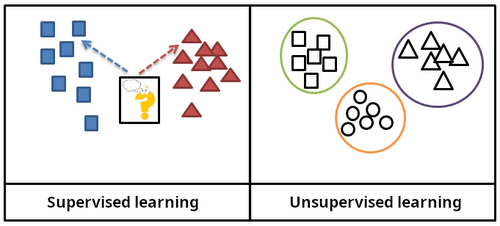
Học có giám sát (Supervised learning)
Theo Wikipedia, supervised learning là "a type of machine learning paradigm where an algorithm learns to map input data to a specific output based on example input-output pairs" — học cách ánh xạ đầu vào sang đầu ra từ các cặp ví dụ có sẵn.
Đây là nhánh phổ biến nhất trong sản xuất. Visa dùng học có giám sát để chấm điểm rủi ro cho từng giao dịch thẻ — và đã ngăn 40 tỷ USD gian lận từ 10/2022 đến 9/2023, gần gấp đôi năm trước. Mô hình nhìn vào hơn 500 thuộc tính mỗi giao dịch và xuất ra điểm rủi ro theo thời gian thực.
Học không giám sát (Unsupervised learning)
Khi không có nhãn, Wikipedia định nghĩa unsupervised learning là khi "algorithms learn patterns exclusively from unlabeled data" — thuật toán tự tìm cấu trúc ẩn trong dữ liệu không nhãn.
Ví dụ thực dụng nhất là phân cụm (clustering) — đẩy 10 triệu khách hàng vào k-means, nó tự nhóm thành 5–10 nhóm hành vi, không cần bạn nói trước nhóm nào là nhóm nào. Marketing dùng đầu ra này để gửi email khác nhau cho từng nhóm. Cùng kỹ thuật cũng được dùng để phát hiện bất thường hoặc gom bài viết theo chủ đề.
Học tăng cường (Reinforcement learning)
Kiểu học gần với cách con người chơi game nhất: thử, sai, điều chỉnh. Ví dụ kinh điển là AlphaGo của DeepMind — sau khi nuốt 30 triệu nước đi của kỳ thủ giỏi, mô hình "was trained further by being set to play large numbers of games against other instances of itself, using reinforcement learning to improve its play" — tự chơi hàng triệu ván với chính mình. Tháng 3/2016 nó đánh bại Lee Sedol 4–1 ở Seoul.

Nguồn: AlphaGo — Wikipedia
Học tăng cường cũng là pha cuối khi huấn luyện ChatGPT, Claude, Gemini — gọi là RLHF. Chi tiết trong LLM là gì.
Machine Learning khác Deep Learning như thế nào?
Deep Learning là một nhánh con của ML, dùng mạng nơ-ron nhiều lớp. Khác biệt thực dụng nhất là dữ liệu. Theo Coursera: "A machine learning algorithm can learn from relatively small sets of data, but a deep learning algorithm requires big data sets that might include diverse and unstructured data".
Gợi ý thực tế:
- Dữ liệu bảng (tabular) — file Excel vài chục nghìn dòng. ML cổ điển (decision tree, XGBoost, random forest) thường thắng deep learning ở đây: đơn giản, nhanh, dễ giải thích.
- Ảnh, âm thanh, văn bản — dữ liệu phi cấu trúc, hàng triệu mẫu. Deep learning gần như là lựa chọn duy nhất. Mọi LLM bạn dùng hôm nay đều là deep learning ở quy mô khổng lồ.
Nói gọn: deep learning là ML, ML là AI. Nhưng không phải mọi ML đều là deep learning.
Khi nào Machine Learning không phải lựa chọn tốt?
ML không phải búa vạn năng. Có vài chỗ nó thua phần mềm truyền thống:
- Khi không có dữ liệu sạch. Mô hình ML chỉ giỏi bằng dữ liệu huấn luyện. Vài trăm dòng lệch không đủ để học gì.
- Khi dữ liệu thay đổi. Mô hình huấn luyện trên hành vi 2023 có thể sai bét trên hành vi 2026 — hiện tượng distribution shift. Bộ lọc spam và mô hình tín dụng phải huấn luyện lại liên tục vì lý do này.
- Khi cần giải thích quyết định. Ngân hàng từ chối khoản vay phải nói được vì sao — yêu cầu pháp lý ở nhiều nơi. Deep learning là hộp đen.
- Khi quy tắc đã rõ. Tính thuế, tính lương, kiểm tra định dạng email — viết quy tắc nhanh hơn, đúng hơn, không cần GPU.
- Khi cần lý luận nhân quả. ML tìm tương quan, không tìm nguyên nhân. Người uống cà phê sống lâu hơn không có nghĩa cà phê làm bạn sống lâu.
Người làm ML giỏi không phải người dùng ML cho mọi thứ. Là người biết khi nào không nên dùng.
Bạn nên bắt đầu học Machine Learning như thế nào?
Tùy mục tiêu, có ba con đường:
- Chỉ muốn dùng sản phẩm ML. Không cần học gì cả. Mở ChatGPT, để Gmail lọc spam. Mọi thứ trong AI là gì đã đủ.
- Muốn xây sản phẩm có ML bên trong. Học Python + scikit-learn trong 2–3 tháng, làm vài bài Kaggle. Bộ "Machine Learning Specialization" của Andrew Ng trên Coursera là điểm bắt đầu phổ biến nhất.
- Muốn nghiên cứu hoặc tối ưu mô hình lớn. Lúc này mới cần đại số tuyến tính, xác suất, giải tích vector.
Lời khuyên thực dụng: chọn một bài toán cụ thể — dự đoán giá nhà ở thành phố bạn, phân loại review sản phẩm — và xây mô hình đầu tiên trong tuần này. Một mô hình tệ chạy được dạy nhiều hơn 10 cuốn sách.
Câu hỏi thường gặp
Machine Learning và AI khác gì nhau? ML là nhánh của AI. AI bao gồm cả hệ thống dựa trên quy tắc cứng (phần mềm cờ vua thập niên 1990, bộ lọc Bayesian đơn giản). Phần lớn AI có ích hôm nay đều là ML, nhưng về khái niệm thì AI rộng hơn.
Học Machine Learning có cần giỏi toán không? Để dùng thư viện (scikit-learn, PyTorch) và làm sản phẩm: chỉ cần Python và thống kê cơ bản. Để nghiên cứu hoặc tối ưu kiến trúc: cần đại số tuyến tính, xác suất và giải tích nhiều biến. Đừng để thiếu toán cản bạn bắt đầu.
Machine Learning có thay thế lập trình viên không? Không thay thế, nhưng đổi kỹ năng. Người viết mã vẫn cần để dựng pipeline, tích hợp mô hình, debug. Cái thay đổi là phần "viết quy tắc kinh doanh" — nhiều quy tắc giờ học từ dữ liệu thay vì gõ tay.
Tôi có thể huấn luyện mô hình ML trên laptop không? Với ML cổ điển (XGBoost, random forest, logistic regression): được, kể cả trên laptop tầm trung. Deep learning quy mô nhỏ (vài chục nghìn ảnh, một CNN nhẹ) cũng được nếu có GPU rời. Còn huấn luyện LLM thì cần cụm GPU đám mây — không phải việc bắt đầu.