Khi ChatGPT trả "Hà Nội" cho câu "Thủ đô của Việt Nam là gì?", nó không hiểu thủ đô là gì. Nó cũng không biết tiếng Việt — chỉ biết những con số thay cho từ. Đó là toàn bộ NLP (natural language processing — xử lý ngôn ngữ tự nhiên) gói gọn trong một ví dụ: máy không hiểu ngôn ngữ, nó biến ngôn ngữ thành số rồi tìm mẫu. Bài này giải thích NLP thực sự là gì, vì sao mọi LLM hôm nay đứng trên 70 năm nghiên cứu NLP, và những kỹ thuật cốt lõi đang chạy âm thầm trong mọi sản phẩm AI bạn dùng.
Nguồn: Natural language processing — Wikipedia
NLP là gì?
Theo Wikipedia, "natural language processing (NLP) is the processing of natural language information by a computer" — NLP là việc máy tính xử lý thông tin ngôn ngữ tự nhiên. "Ngôn ngữ tự nhiên" ở đây là tiếng Việt, tiếng Anh, tiếng Nhật — đối lập với ngôn ngữ hình thức như Python hay SQL.
Cụm "xử lý" quan trọng hơn người ta tưởng. Máy không hiểu, không cảm nhận, không có ý niệm về Hà Nội. Nó chuyển chuỗi ký tự thành số, đẩy số qua các phép tính, rồi xuất ra chuỗi ký tự khác. Sự "thông minh" mà bạn nhìn thấy chỉ là toán ở giữa.
NLP nằm trong AI, giao với deep learning ở phần lớn ứng dụng hiện đại, và bao trùm LLM. Mọi LLM đều là NLP, nhưng không phải mọi NLP đều là LLM. Bộ lọc spam Gmail dùng NLP. Google Translate năm 2010 dùng NLP. ELIZA năm 1966 cũng là NLP — không có một dòng deep learning nào.
NLP hoạt động như thế nào?
Hầu hết hệ NLP đi qua ba bước:
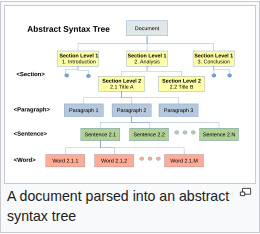
- Tách văn bản thành đơn vị nhỏ — gọi là tokenization. Câu "Tôi yêu Hà Nội" có thể chia thành
["Tôi", "yêu", "Hà", "Nội"]hoặc["T", "ôi", " yêu", " Hà", " Nội"]tùy mô hình. - Biến mỗi token thành số (vector) — gọi là embedding. Token "Hà Nội" được ánh xạ thành dãy vài trăm số thực. Hai từ nghĩa gần nhau (Hà Nội, Sài Gòn) có vector gần nhau trong không gian số.
- Đẩy vector qua mô hình — quy tắc cứng, hoặc mạng nơ-ron hàng tỷ tham số. Mô hình xuất ra: số, nhãn, hoặc dãy vector mới mà ta dịch ngược về văn bản.
Khi bạn gõ "Thủ đô của Việt Nam là", ChatGPT tách thành token, biến thành vector, đẩy qua mô hình transformer. Mô hình trả về xác suất cho từng token có thể đứng tiếp. Token "Hà Nội" có xác suất cao nhất nên nó xuất ra "Hà Nội". Toàn bộ "sự hiểu biết" là phép nhân ma trận.
NLP gồm những kỹ thuật cốt lõi nào?
NLP không phải một việc, mà là một họ bài toán.
Tokenization
Bước đầu của mọi pipeline NLP. Với tiếng Anh, tách theo dấu cách là đủ trong hầu hết trường hợp. Với tiếng Việt, mọi chuyện khó hơn — "học sinh" là hai âm tiết nhưng một từ, "máy tính" cũng vậy. Sai bước này, mô hình hiểu sai cấu trúc câu.
Named Entity Recognition (NER)
Trích xuất tên riêng, địa danh, ngày tháng, số tiền từ văn bản thô. Khi bạn dán hợp đồng vào Claude và yêu cầu "liệt kê các bên ký kết và ngày hiệu lực", NER là kỹ thuật đứng sau. Y tế dùng cùng kỹ thuật này để rút thông tin bệnh nhân từ hồ sơ bác sĩ.
Sentiment analysis
Phân loại thái độ văn bản: tích cực, tiêu cực, trung lập. Theo Elastic, "sentiment analysis is a natural language processing (NLP) technique that uses computational linguistics and machine learning to detect the emotional tone behind text data" — sentiment analysis là kỹ thuật NLP dùng ngôn ngữ học tính toán và học máy để dò sắc thái cảm xúc. Marketing dùng nó để theo dõi cảm nhận khách hàng; chăm sóc khách hàng dùng để ưu tiên email giận dữ.
Machine translation
Dịch tự động giữa các ngôn ngữ. Google Translate là ví dụ rõ nhất — và cũng là minh họa hay nhất cho cách NLP đã thay đổi. Câu chuyện đó ở phần tiếp theo.
| Tác vụ NLP | Bạn gặp ở đâu hằng ngày |
|---|---|
| Tokenization | Mọi prompt ChatGPT (ngầm) |
| NER | Gmail rút lịch hẹn từ email, Apple Mail tóm tắt |
| Sentiment analysis | Tag review tích cực/tiêu cực trên Shopee |
| Machine translation | Google Translate, DeepL |
| Speech recognition | Siri, Google Assistant, Zalo AI Voice |
| Question answering | ChatGPT, Claude, Perplexity |
NLP đã đi qua ba thời kỳ nào?
Nguồn: ELIZA — Wikipedia
NLP không sinh ra cùng ChatGPT năm 2022. Nó có 70 năm lịch sử, chia thành ba thời kỳ.
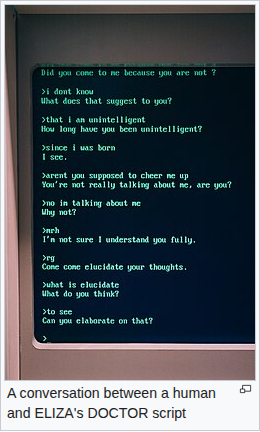
Thời kỳ ký hiệu (1950–1990). NLP đời đầu dựa trên quy tắc viết tay. Ví dụ kinh điển là ELIZA — "an early natural language processing computer program developed from 1964 to 1967 at MIT by Joseph Weizenbaum". Script DOCTOR "simulated a psychotherapist of the Rogerian school (in which the therapist often reflects back the patient's words to the patient)" — bắt chước bác sĩ trị liệu Rogers bằng cách phản chiếu lời bệnh nhân. ELIZA không hiểu gì, chỉ khớp mẫu — nhưng người dùng vẫn tưởng nó hiểu.
Thời kỳ thống kê (1990–2015). "Starting in the late 1980s, however, there was a revolution in natural language processing with the introduction of machine learning algorithms" — cuối thập niên 1980, học máy bước vào NLP. Thay vì viết quy tắc, người ta cho máy đọc văn bản lớn và để nó tự rút mẫu thống kê. Google Translate giai đoạn 2007–2016 dùng cách này.
Thời kỳ neural (2015–nay). "Since 2015, neural network–based methods have increasingly replaced traditional statistical approaches" — mạng nơ-ron dần thay thống kê. Bước nhảy lớn nhất đến từ bài báo "Attention Is All You Need" công bố 12/6/2017 bởi tám tác giả Google, giới thiệu kiến trúc transformer. Bài báo "has been cited more than 173,000 times, placing it among the top ten most-cited papers of the 21st century" tính đến 2025, và transformer trở thành "the main architecture of a wide variety of artificial intelligence, including large language models". Đến 2020, Google Translate cũng đã bỏ NMT cũ để dùng transformer.
NLP có những giới hạn gì bạn cần biết?
NLP không phải phép màu. Vài giới hạn vẫn tồn tại sau bảy thập kỷ nghiên cứu.
Mơ hồ ngữ nghĩa. "Cô ấy thấy người đàn ông với ống nhòm" — ai cầm ống nhòm? Mô hình đoán theo xác suất, không theo lý lẽ.
Mỉa mai và châm biếm. Theo Elastic, "detecting and understanding irony and sarcasm remains a significant challenge in sentiment analysis". Một review 5 sao viết "tuyệt vời, hỏng sau ba ngày" sẽ bị sentiment analysis truyền thống chấm tích cực.
Thiên vị từ dữ liệu. Mô hình kế thừa định kiến trong văn bản huấn luyện. Hệ NLP trước 2020 thường gán "y tá" cho nữ và "kỹ sư" cho nam — vì văn bản huấn luyện viết thế.
Tiếng Việt thiệt thòi. Dữ liệu tiếng Việt ít hơn tiếng Anh nhiều lần. Tách từ khó vì khoảng trắng tách âm tiết chứ không tách từ. Mô hình NLP cho tiếng Việt thường yếu rõ rệt với chuyên ngành hẹp như luật, y khoa.
Vẫn không "hiểu". Transformer xử lý ngôn ngữ tốt đến mức nhiều người gọi là "hiểu". Nhưng cơ chế vẫn là khớp mẫu thống kê trên token, không phải suy luận về thế giới. Đây là lý do LLM bịa số liệu mà không tự biết.
NLP khác LLM ở điểm nào?
Nguồn: Attention Is All You Need — Wikipedia
LLM là một dạng cụ thể của NLP — dùng deep learning quy mô rất lớn để sinh ngôn ngữ. NLP rộng hơn, bao gồm cả:
- Bộ phân loại spam dùng Naive Bayes — chạy được trên laptop, mô hình vài MB.
- Hệ trích xuất hóa đơn dùng regex và NER cổ điển — không cần GPU.
- Mô hình dịch thống kê đời 2010 — vẫn dùng trong vài hệ thống nhúng.
Khi nào nên dùng NLP "không-LLM"? Khi tác vụ hẹp, dữ liệu nhãn sẵn, cần chi phí thấp và tốc độ cao. Phân loại 100 triệu email mỗi ngày bằng GPT-4 tốn vài triệu USD; bằng classifier nhỏ chỉ tốn vài chục USD và nhanh gấp 100 lần.
Khi nào LLM thắng? Khi tác vụ mở, ít dữ liệu nhãn, hoặc cần kết hợp nhiều bài toán cùng lúc — đọc hợp đồng → tóm tắt → trả lời câu hỏi → soạn email phản hồi. Một mô hình thay được mười.
Câu hỏi thường gặp
Tôi có cần học NLP để dùng ChatGPT không? Không. Dùng ChatGPT chỉ cần biết gõ prompt rõ ràng. Học NLP cần thiết nếu bạn muốn tự xây sản phẩm AI, tinh chỉnh mô hình, hoặc làm nghiên cứu.
Học NLP cần biết những gì? Python là tối thiểu. Sau đó: học máy cơ bản, đại số tuyến tính ở mức hiểu vector và ma trận, và một thư viện thực hành (HuggingFace Transformers là tiêu chuẩn). Hiểu kiến trúc transformer giúp đọc được giấy nghiên cứu mới.
NLP tiếng Việt có khó hơn tiếng Anh không? Có. Dữ liệu ít hơn nhiều lần, tách từ phức tạp hơn vì khoảng trắng tách âm tiết, và dấu thanh sai dễ làm mô hình hiểu nhầm. Underthesea và VinAI PhoBERT là hai dự án mã nguồn mở cho tiếng Việt.
NLP có giống "lập trình ngôn ngữ tư duy" không? Không liên quan. Neuro-linguistic programming là phương pháp tâm lý/giao tiếp gây tranh cãi từ thập niên 1970. Trong tài liệu AI, "NLP" luôn là natural language processing.